LeadSignal: AI Lead Scoring with Claude API
LeadSignal scores inbound CRM leads 0–100 and enriches each record with an SDR-readable fit narrative — built for RevOps teams who need AI judgment without losing auditability.
At a glance
- Problem: Sales teams drown in inbound leads; black-box ML scores erode trust, and rules-only systems miss nuance in free-text company descriptions.
- Approach: Transparent rules engine for the numeric score; Claude API for qualitative enrichment (fit narrative + next action). The two layers are deliberately decoupled.
- Stack: Next.js 14 · TypeScript · Supabase · Claude API · Python/Faker synthetic data pipeline.
- Headline result: Hot-tier leads convert at 28.0% vs 12.2% base rate; precision@50 = 36% (2.9× random ordering).
The problem
Inbound lead volume is a RevOps problem dressed up as a sales problem. Marketing generates contacts; CRMs fill with incomplete firmographics, stale engagement fields, and company descriptions that no spreadsheet formula can read reliably. A Director who downloaded two whitepapers and a VP who requested a demo look similar in a flat contact list — but they are not the same opportunity.
Most portfolio "AI lead scoring" demos pick one extreme: either a rules spreadsheet with no intelligence, or an LLM wrapper with no pipeline. Neither survives contact with a real sales org. Rules-only systems cannot interpret "recently raised Series B and scaling go-to-market" as a buying trigger. Pure LLM scoring is expensive, non-deterministic, and impossible to defend when a rep asks "why is this an 82?"
After eleven years at a HubSpot Platinum Partner agency, the adoption bottleneck I kept seeing was not model accuracy on day one — it was trust. Marketing ops need to tune weights in a code review. SDRs need a narrative they can act on. Finance needs cost controls on API calls. LeadSignal is not to prove that AI can score leads, but to show how production-style AI integration should sit alongside auditable RevOps infrastructure.
Architecture & logic
A lead enters the pipeline as raw CRM-style JSON — firmographics, engagement counters, a free-text company description, and a hidden converted flag used only for backtesting. Nothing calls Claude on page load.
synthetic_leads.json
│
▼
lib/scoring.ts rules engine → 0–100 score + tier (HOT/WARM/COLD)
│
▼
scripts/enrich_leads.ts batch Claude → fit_narrative, recommended_action
│
├──► enrichments.json (file fallback)
▼
Supabase (optional) denormalised leads table
│
▼
Next.js dashboard / lead table · /validate backtest
/api/enrich live re-enrich (rate-limited)Why rules for scoring, Claude for enrichment
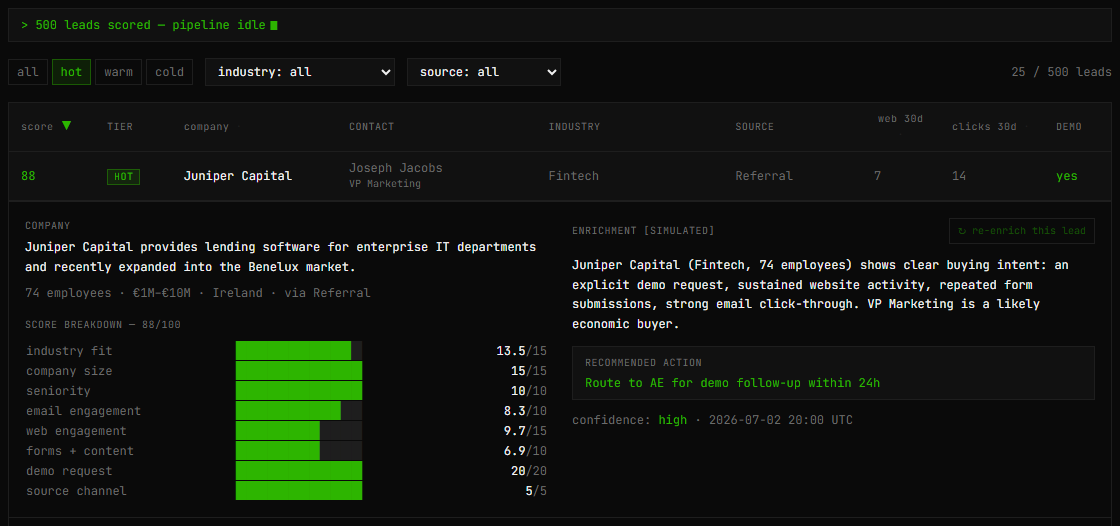
The numeric score is 100% deterministic. Every weight is documented in lib/scoring.ts and rendered as a per-lead breakdown table in the UI — industry fit (15 pts), company size (15), seniority (10), engagement signals (60). Tiers: HOT ≥ 75, WARM 45–74, COLD < 45.
I rejected end-to-end LLM scoring for three concrete reasons:
- Auditability — When routing workflows depend on a score, the answer to "why?" must be a breakdown table, not a model shrug.
- Cost and latency — Scoring 500 leads on every dashboard refresh would mean ~500 API calls per page view. Rules run in microseconds; Claude runs once at batch time.
- Determinism — The same lead always gets the same score. Routing logic, A/B tests, and regression checks require that stability.
Claude is asked to do what rules cannot: read the company description and engagement pattern, then write a two-line rationale in SDR language — why this lead fits, and what to do next. The prompt explicitly forbids re-scoring; Claude receives the rules-engine score as context but never changes it. If the narrative is wrong, the score remains defensible. If the weights drift, the narrative still surfaces useful context. Independent failure modes.
Enrichment and write-back
Batch enrichment (npm run enrich) scores every lead, calls Claude with a structured JSON response schema (fit_narrative, recommended_action, confidence), and writes results to data/enrichments.json. When Supabase is configured, the same fields upsert into a denormalised leads table server-side via the service-role key.
The only live API call at request time is the re-enrich button on an individual lead. That route is rate-limited per IP (default 5/hour), can be disabled entirely via ENRICH_LIVE_ENABLED=false, and falls back to a labelled mock when no API key is present. The dashboard never blocks on Claude.
Benchmarks & results
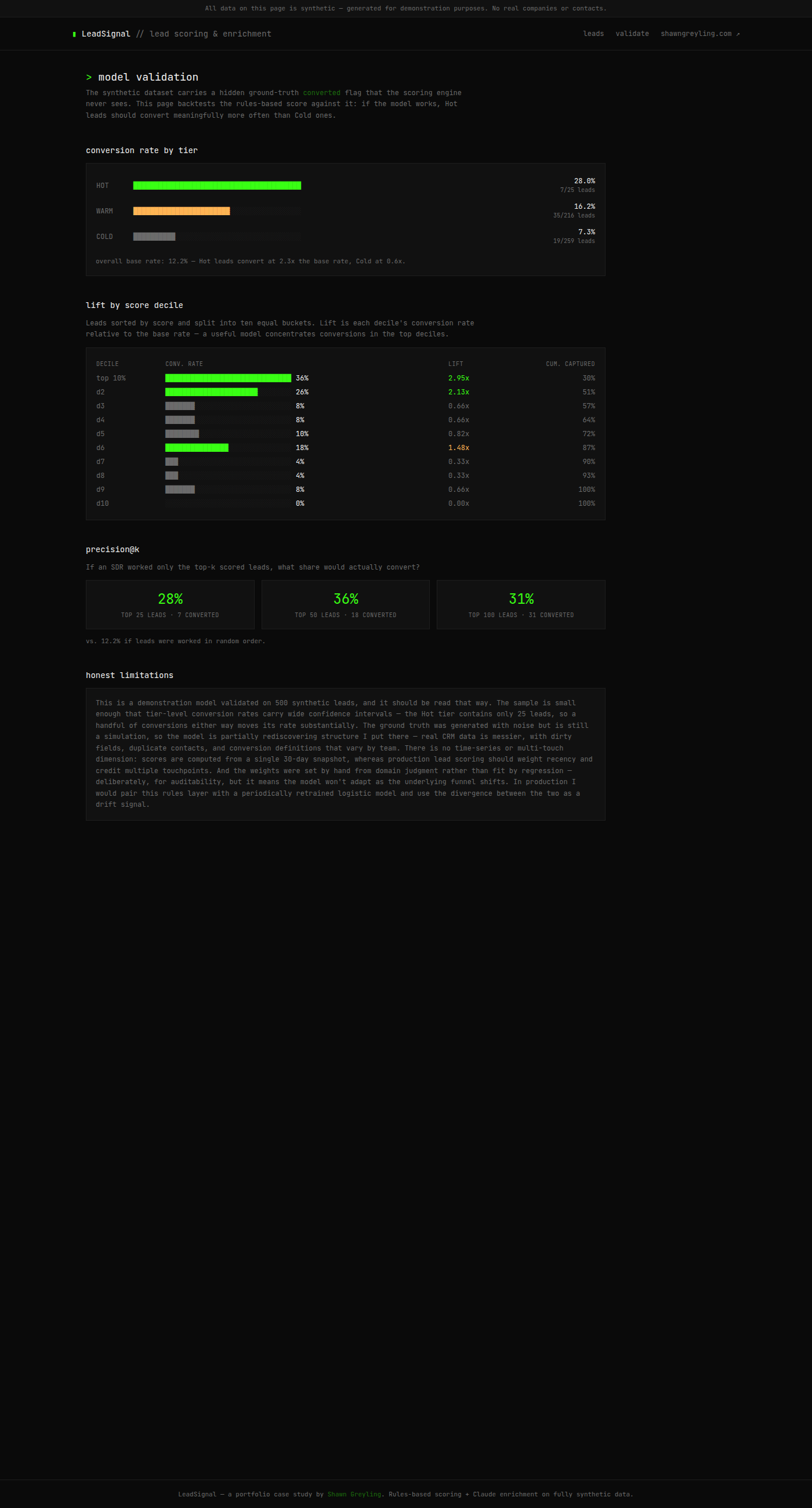
Validation runs on /validate against the hidden converted flag — 500 synthetic leads, 12.2% overall conversion rate. The scoring engine never sees the flag during scoring; this is a held-out backtest, not training feedback.
| Tier | Leads | Conversion rate | Lift vs base | | --- | ---: | ---: | ---: | | HOT | 25 | 28.0% (7/25) | 2.3× | | WARM | 216 | 16.2% (35/216) | 1.3× | | COLD | 259 | 7.3% (19/259) | 0.6× |
Precision@k — if an SDR worked only the top-scored leads:
| Top-k | Converted | Precision | vs random (12.2%) | | --- | ---: | ---: | ---: | | 25 | 7 | 28% | 2.3× | | 50 | 18 | 36% | 2.9× | | 100 | 31 | 31% | 2.5× |
Decile lift — top score decile converts at 36% (2.95× base); top two deciles capture 51% of all conversions. Deciles 7–10 show near-zero lift — the model correctly deprioritises the long tail.
Scoring consistency and latency
The rules layer is fully deterministic: re-running scoreLead() on the same input always returns the same score and breakdown. There is no score variance to report — that is intentional.
Claude enrichment is non-deterministic by design. Re-enriching the same lead can produce different narrative wording or confidence labels while the numeric score stays fixed. I did not run a formal consistency benchmark (e.g. N re-enrichments per lead with semantic-similarity scoring) in this portfolio build; that would be a sensible production gate before routing workflows on LLM output.
Latency splits cleanly by layer:
| Layer | Latency | Notes | | --- | --- | --- | | Rules scoring | Sub-millisecond per lead | Pure TypeScript, no I/O | | Batch enrichment | ~500 sequential API calls at batch time | Concurrency pool of 4; not measured wall-clock in CI | | Live re-enrich | One Claude call per button click | Rate-limited; typical Sonnet latency applies |
No formal p50/p95 latency table was captured for this demo. In production I would log enrichment duration per call and alert on p95 regression.
Honest limitations
500 synthetic leads is a small sample. The Hot tier holds only 25 leads — a handful of conversions either way moves its rate substantially (wide confidence interval). The ground truth is simulated with injected noise, so the model partially rediscovering structure I put there is expected; real CRM data is messier. There is no time-series or multi-touch attribution — scores come from a single 30-day snapshot. Weights are hand-set for auditability, not regression-fit, so they will not adapt as the funnel shifts.
The full validation page with decile charts lives in the LeadSignal /validate route — this section summarises those results.
What I'd do differently
Pair rules with a drift alarm. I would keep the auditable rules layer as the routing default and run a periodically retrained logistic model in parallel. Divergence between the two is the drift signal — when they disagree systematically, weights need tuning or the funnel has shifted.
Formalise enrichment QA. Before trusting Claude narratives in a workflow, I would benchmark narrative consistency (same lead, N runs) and spot-check against human SDR labels on a held-out set. Confidence labels should correlate with actual conversion lift, not just model self-assessment.
Time-aware scoring. Single-snapshot scoring ignores recency decay. Production scoring should weight the last 7 days more heavily than days 8–30, and credit multi-touch sequences rather than treating engagement counters as static.
Real data, small scope. Synthetic data was the right choice for a public portfolio demo (no PII, reproducible). The next validation step is a anonymised slice of real CRM exports — even 200 leads — to stress-test field dirtiness and duplicate contacts.
Stack & links
- Next.js 14 (App Router) · TypeScript · Tailwind CSS
- Supabase (Postgres, optional — demo runs file-only)
- Claude API (
claude-sonnet-4-20250514) · Python + Faker for synthetic data generation - GitHub: LeadSignal source
Related portfolio work: DocSignal (hybrid RAG retrieval), SignalVision (ONNX int8 quantization for browser inference).